@thierry.f.78
Alors perso je signe pas pour 7 ou 8 épisodes. 
@JeromeB
En fait avec la latence il y a pas vraiment de spoiler, car la cause c’est de la physique, il y a des cas d’utilisations ou elle est négligeable et d’autres ou elle ne l’est malheureusement pas. Et quand tu touches ces limites c’est souvent douloureux.
Exemple un peu grossier et volontairement simpliste:
Tu veux envoyer un paquet (une io) vers un site distant via un réseau. La limite c’est la « vitesse de la lumière ».
Bon l’ordre de grandeur grosse maille c’est 5µs / km. (célérité de la lumière dans le verre bla bla, on va pas chipoter)
Si tu fais 1000km * 5µs = 5ms, et ces 5ms elles sont impossibles à compresser. (sauf avec la Dolorean de Doc)
Et là je fais cadeau des temps de commutation des équipements, des congestions et des erreurs possibles sur le réseau etc…
5ms c’est plus vraiment négligeable. C’est le temps de réponse d’un disque mécanique.
Le truc rigolo, c’est que souvent tu veux un acquittement de cette io par ton stockage.
Bing 5ms de plus pour le recevoir et que ton système dise, ok l’io a été écrite. Spoiler, en asynchrone tu vas justement pas attendre cette acquittement pour validé l’io, elle se fera en « background ».
Zut c’est balo on venait de mettre un baie full flash de la mort sur le site distant et ça se traine lamentablement… 
Tu notes aussi que tu peux grossir la taille du tuyau 1Gb, 10 Gb, 100Gb, ça change rien en fait.
Ton io mettra toujours au minimum 5ms de a vers b.
Pour que ça change il va falloir paralléliser les flux. Et donc + ou - « masquer » cette latence, en augmentant le débit.
Pour l’illustrer, tu peux le voir avec un ftp car globalement tu streams les octets les un à la suite des autres.
Après fun with flags, voici fun with linux (Amy cher assistante sortait moi le tc qui va bien) :
Test 1:
1 flux, latence réseau round trip time = 100ms (0,1s) taille du paquet max ethernet = 1500 Bytes
Théoriquement.
Tu peux donc envoyer, 10 paquets en 1s.
10 * 1500 = 15000B/s ~ 14,6 MB/s théorique :
Petit test avec la loopback de mon laptop, histoire de pas trop se faire limiter par le réseau. Le sous système disque est un ssd.
Création d’un fichier de 1GB avec du random pour le test
dd if=/dev/random of=testfile_1G bs=1024k count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 33.1674 s, 32.4 MB/s
Petit cp pour voir le temps de copie et que ce ne soit pas le disque qui va nous limiter.
sync && time cp testfile_1G /tmp
real 0m2.210s
user 0m0.024s
sys 0m1.061s
1024MB / 2,210s = 463MB/s (un ssd normal quoi. Si vous trouvez le débit faible, j’accepte un don d’un NVMe 1TB)
Ok si le débit théorique calculé est juste le ssd devrait pas être le problème.
Set du mtu a 1500 sur la loopback
sudo ip link set dev lo mtu 1500
Check du ping sur la loopback:
PING localhost.localdomain (127.0.0.1) 56(84) bytes of data.
64 bytes from localhost.localdomain (127.0.0.1): icmp_seq=1 ttl=64 time=0.079 ms
64 bytes from localhost.localdomain (127.0.0.1): icmp_seq=2 ttl=64 time=0.040 ms
64 bytes from localhost.localdomain (127.0.0.1): icmp_seq=3 ttl=64 time=0.073 ms
Oui la loopback ca envoie,
il y a pas trop de lantence
Ajout de la latence sur la loopback
sudo tc qdisc add dev lo root netem delay 50ms
ping localhost
PING localhost.localdomain (127.0.0.1) 56(84) bytes of data.
64 bytes from localhost.localdomain (127.0.0.1): icmp_seq=1 ttl=64
time=100 ms
64 bytes from localhost.localdomain (127.0.0.1): icmp_seq=2 ttl=64 time=100 ms
Voila le round trip time est maintenant de 100ms. 
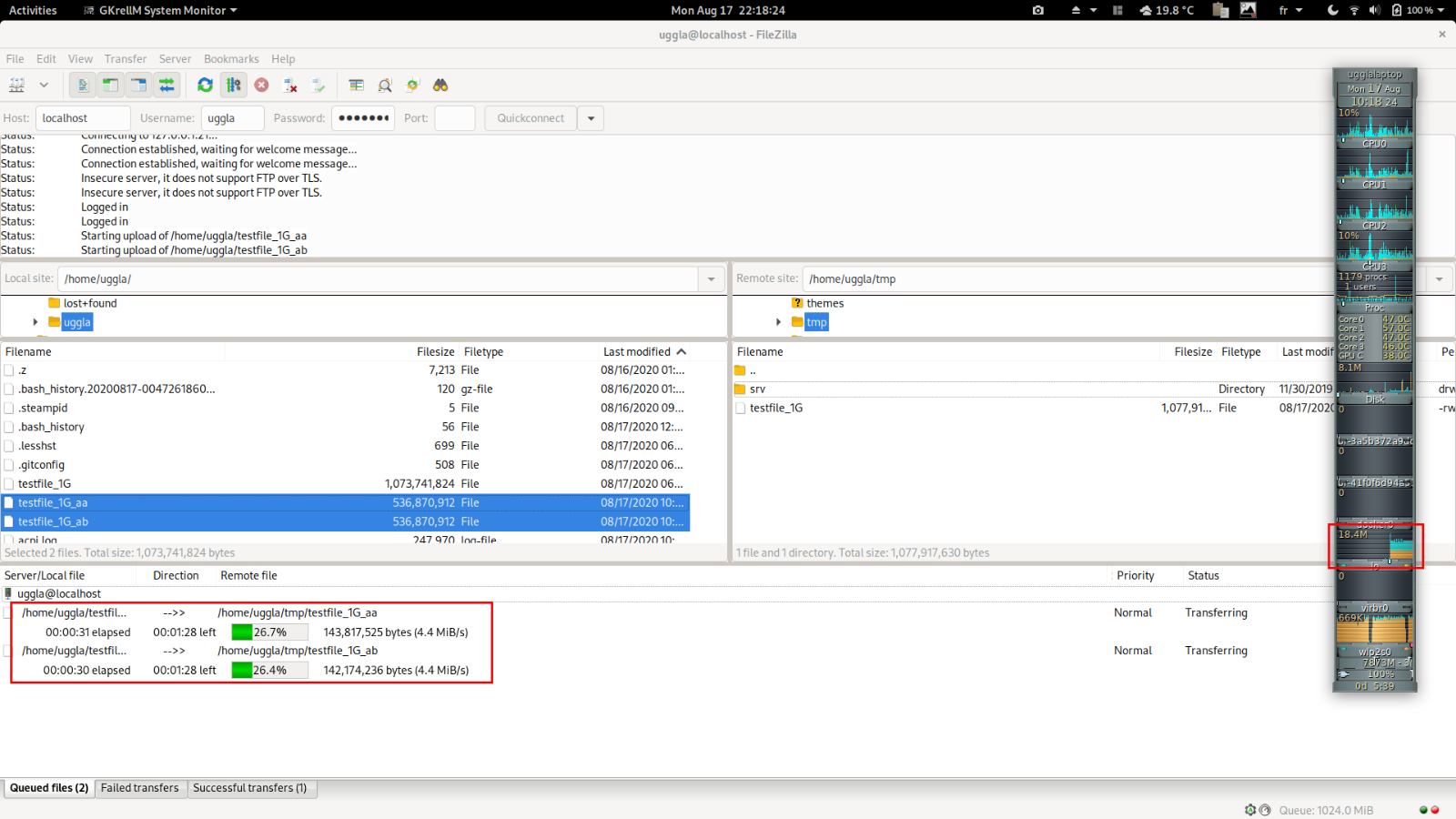
Ensuite je lance mon ftp entre le fichier dans ma home vers /tmp via ftp.
Si je regarde mon fidèle gkrellm, 10MB/s (8.2MB/s a moment du screenshot), c’est horrible, même moins que le théorique calculé.
A noter que ici mon host fait client et serveur, cf le flux orange (tx) et bleu (rx)
Et donc le flux global de 10MB/s et divisé par 2. En utile c’est environ 4,5 MB/s (cf screenshot)
File transfer successful, transferred 1,077,917,630 bytes in 240 seconds
Test 2:
2 flux, latence réseau round trip time = 100ms (0,1s) taille du paquet max ethernet = 1500 Bytes
Je coupe mon fichier initial en 2 :
split -n 2 testfile_1G testfile_1G_
.rw-rw-r-- uggla uggla 512 MB Mon Aug 17 22:13:49 2020 testfile_1G_aa
.rw-rw-r-- uggla uggla 512 MB Mon Aug 17 22:13:52 2020 testfile_1G_ab
Et je lance le ftp:
Mon débit est ~doublé même si ma latence est identique.
~20MB/s
File transfer successful, transferred 538,958,338 bytes in 117 seconds
Status: File transfer successful, transferred 538,959,292 bytes in 118 seconds
Test 3:
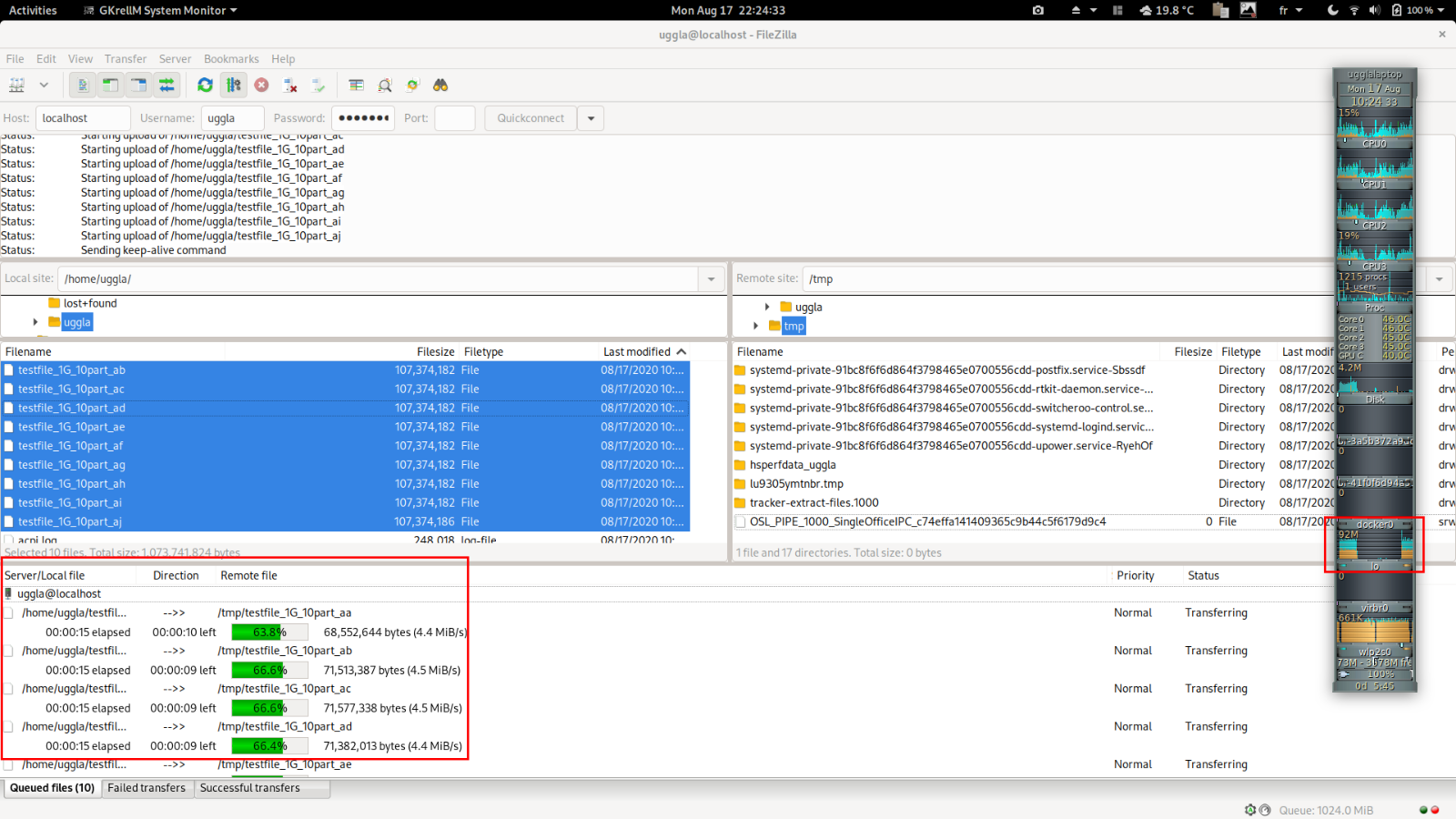
La je suis chaud, Amy on lance avec 10 flux en parallèle.
10 flux, latence réseau round trip time = 100ms (0,1s) taille du paquet max ethernet = 1500 Bytes
split -n 10 testfile_1G testfile_1G_10part_
.rw-rw-r-- uggla uggla 102.4 MB Mon Aug 17 22:19:05 2020 testfile_1G_10part_aa
.rw-rw-r-- uggla uggla 102.4 MB Mon Aug 17 22:19:06 2020 testfile_1G_10part_ab
.rw-rw-r-- uggla uggla 102.4 MB Mon Aug 17 22:19:06 2020 testfile_1G_10part_ac
.rw-rw-r-- uggla uggla 102.4 MB Mon Aug 17 22:19:07 2020 testfile_1G_10part_ad
...
~100 MB/s youpi 
Status: File transfer successful, transferred 107,792,010 bytes in 23 seconds
Status: File transfer successful, transferred 107,792,422 bytes in 23 seconds
Status: File transfer successful, transferred 107,790,652 bytes in 23 seconds
Status: File transfer successful, transferred 107,791,849 bytes in 23 seconds
...
On est quand même passé de 240s à 23s pour transferer le même contenu.
Test 4:
1 flux, latence réseau round trip time ~ 0,040ms taille du paquet max ethernet = 1500 Bytes
Je retire la latence de la loopback
sudo tc qdisc del dev lo root netem
ping localhost
PING localhost.localdomain (127.0.0.1) 56(84) bytes of data.
64 bytes from localhost.localdomain (127.0.0.1): icmp_seq=1 ttl=64 time=0.040 ms
64 bytes from localhost.localdomain (127.0.0.1): icmp_seq=2 ttl=64 time=0.063 ms
File transfer successful, transferred 1,077,917,630 bytes in 2 seconds.
Mon ssd redevient l’élément à la latence la plus grande et limite le débit.
On plafonne donc au débit de mon ssd ~ 450MB/s.
A noter aussi que tu peux jouer sur le mtu, si j’utilisais des jumbo frame par exemple.
Si tu passes le mtu à 9000, bein je te laisse faire le test mais ça change pas grand chose dans cet exemple.
Le mtu va jouer sur la fragmentation, tu vas donc avoir moins de paquet ack a traiter. Mais je pense que sur un aussi petit débit ça ne change pas grand chose en fait. Ca serait pas le cas sur un système qui prend cher en io reseau. Mais ça peut aussi etre contre productif dans certain cas. (si l’appli fait de toute petite io)
Ici en faisant plusieurs fichiers, je peux paralléliser mon flux.
Mais si c’est pas le cas alors cela devient compliqué. Et des applis qui parlent avec un seul flux, il y en a plein. (un peu comme les applis mono thread) et ces applications vont être super sensible à la latence et dans certains cas, ça peut complétement faire échouer des migrations ou des mises en production. Et l’illustration de cela on peut l’aborder dans un podcast. Si @cchaudier , @Thomas sont ok.






 ). Sur le deuxième lien, plusieurs passages étaient possibles, notamment un plus long ~120km mais géographiquement très éloigné du premiers, mais nous n’avions pas pris cette option car sur ce chemin il fallait des répéteurs avec un impact sur la latence (pas énorme quand même) et le cout si je me souviens bien.
). Sur le deuxième lien, plusieurs passages étaient possibles, notamment un plus long ~120km mais géographiquement très éloigné du premiers, mais nous n’avions pas pris cette option car sur ce chemin il fallait des répéteurs avec un impact sur la latence (pas énorme quand même) et le cout si je me souviens bien.